Intro
La rédemption ou redeem ne vous dit peut-être rien. Dans le monde numérique si je puis dire il s’agit d’un concept où l’on peut racheter (souvent gratuitement) la copie numérique d’un produit physique que l’on possède. Il peut s’agir d’un contenu vidéo, d’un jeu, d’un livre ou des titres audios.
Pour les produits les plus récents, certains fabricants et revendeurs intègrent un code d’activation lié a une plateforme. On peut citer ultraviolet pour la vidéo et nvidia-steam pour les jeux vidéos. Mais pour les produits plus anciens c’est plus compliqué. Si pour les œuvres tombées dans le domaine public, il est facile de trouver des copies numériques. Ce n’est pas toujours le cas pour des produits de notre enfance ou de celle de nos parents. Les avancées de la numérisation de beaucoup de produit changent la donne. Certains acteurs se lancent dans le marché avec des modèles économiques qui font le yoyo entre la tarification a la demande et l’abonnement. On imagine bien les ayants droits lorgnés sur cette rente financière. Mais c’est un débat dans lequel je ne vais pas rentrer.
Pour permettre la « redeem » de produits un peu plus ancien, il faut compter sur les plateformes qui ont numérisé des volumes colossaux de contenus. Contenus pour lesquels les codes d’activation n’existent pas. Touefois il existe des solutions alternatives, et le code barre ou EAN (en Europe) fait partie de la solution. Moyennant un compte sur la dite plateforme, il suffit d’envoyer une photo du code barre et de la copie physique du produit pour accéder a la version numérique proposée.
Pratique oui, mais pour les offres illimitées, c’est un petit peu la porte ouverte a toutes les fenêtres. On peut alors imaginer tout un tas de scénario comme une librairie ou un centre culturel ou commercial pour scanner tout le contenu disponible et l’ajouter sa collection. D’un point de vue logiciel, mettre des quotas requérir la localisation de l’utilisateur pour utiliser le service et confronter sa position a celle d’une base de connaissance de lieux n’est pas très difficile.
Mais quid d’une personne qui utiliserait un générateur de code ou les photos de produits disponibles sur internet via Google Images ou le site d’un marchand et qui prendrait ainsi en photo son écran. C’est la tache qui m’a été confiée et que je vais développer ici, si la tache peut être confiée a des humains, cela représente un coup et induit une latence dans l’utilisation du service. Se pose alors la question comment détecter automatiquement a grande échelle que la photo prise par l’utilisateur n’est pas une photo d’écran c’est la que nous entrons dans le vif du sujet du Machine Learning.
Mais en fait on veut faire quoi ?
Pour faire simple, on souhaite que chaque nouvelle demande de rédemption (qu’il s’agisse d’un code barre scanné ou d’une photo de produit) passe au travers d’une scanner qui décide si la rédemption doit-être acceptée ou refusée. Il s’agit d’un double défi, d’une part de détecter au mieux les fraudeurs, d’autre part de rejeter au minimum les demandes légitimes.
Techniquement comment ça se passe ?
Il faut tout d’abord se poser avec une série de photo, des légitimes bien sur, et une sélection de photos suspectes ou clairement identifiées comme étant illégitimes. Même si l’on ne doit présumer de rien, une partie du travail se fait a l’intuition sur les éléments de culture que l’on peut avoir.
Le domaine de l’image est riche, on peut travailler au niveau des pixels :
- couleur R,G,B
- luminosité
- intensité des couleurs
- similarité sur des groupes de pixels
Mais on peut également représenter l’image dans sa globalité d’un point de vue spectre et fréquences (une petite pensée aux cours de traitement du signal en licence et la galère avec les transformées de Fourrer).
Il est possible de croiser les multiples dimensions et ainsi augmenter la complexité de l’analyse. Il est important de garder a l’esprit que les choses que l’œil peut voir, qui permettent de distinguer 2 images, la machine pourra apprendre a en faire de même sous réserve que l’on mette sous le nez la bonne représentation de ce que l’on voit. Question de secret industriel je ne dirai pas quelle méthode a été utilisée, je peux par contre détaillé le processus d’analyse une fois toutes les dimensions mises sur le tapis.
Dans notre cas, chaque image est soumise a une moulinette de vectorisation, un grand mot pour dire que l’on va transformer une bouillie de pixels en un tableau de quelques nombres. Voici un exemple d’image et la représentation associée vectorielle associée :

screen_1.jpg 40 111 87 140 123 151 260 50530 6599 455230 19346 233551 209202 165288 167805 181076 41030 83000 69956 115259 73591 23527 57115 42206 31612 27977 27407 27710 26913 26450 31064 23527 18309 22768 22730 22242 20773 20521 21460 18554 17725 17174 16334 17026 17037 17024 17066 16157 15651 15446 15459 16179 17559 18717 19653 18597 17467 15891 15812 14942 15131 15061 14778 14909 14750 15361 15990 16964 17527 18115 18608 18378 18758 18561 18729 18569 18283 17977 17297 16124 15067 14223 13553 12898 12373 11947 11640 11483 11128 11185 10817 10667 11115 10701 10732 10882 10684 10642 10105 10042 9893 9612 9187 9169 8669 8462 8181 7883 7704 7485 7290 7159 7181 6907 7013 6476 6843 6629 6518 6541 6471 6460 6470 6067 5963 5870 5455 5191 5252 5207 5229 5023 5115 5139 4900 5016 5004 5097 5057 5070 5172 5224 5270 5400 5456 5340 5664 5902 6201 6314 6607 6817 7098 7455 7566 8157 8171 8519 9008 9457 9728 10216 10703 11103 11337 11623 12237 12438 12900 13722 14366 15253 15750 16135 17071 17081 17668 18302 19079 19152 19391 19302 19199 19251 19250 18873 19042 18841 18905 18831 19119 19032 19307 19301 19416 19458 19698 20033 20223 20171 20561 20568 20834 20870 21051 21196 21636 21733 22152 22549 22698 22743 22834 22406 22351 22275 21978 21461 20788 19905 19425 18151 17568 16790 15912 14337 13386 12256 11194 9958 9228 8280 7670 7009 6325 5803 5292
Si l’on peut facilement distinguer visuellement parmi les 2 images ci-dessous quelle est la vraie de la fausse, trouver une règle qui permet de distinguer les 2 tableaux est beaucoup moins évidente.


1009_true_.txt 1 5:255 6:255 7:245 8:255 10:0 11:3 12:0 13:0 15:141.363 16:127.456 17:111.685 18:126.835 20:40.775 21:50.2095 22:57.4233 23:49.9367 25:1.13305 26:-0.363706 27:-0.487771 28:-0.198741 30:-0.961372 31:0.224701 32:0.546399 33:-0.0170855
1013_screen_.txt -1 5:255 6:239 7:235 8:255 10:0 11:3 12:0 13:0 15:108.277 16:101.579 17:102.785 18:104.214 20:92.5905 21:87.7692 22:84.6472 23:88.396 25:-1.71085 26:-1.58567 27:-1.60809 28:-1.63152 30:0.25365 31:0.41701 32:0.298133 33:0.326747
Je précise également que la question de la compression des images se pose également. Pour les scanners de code barre par exemple la résolution est très mauvais alors qu’un appareil photo même de téléphone basique peut fournir un cliché honnête.Il pourrait être tentant de dire qu’il vaut mieux une meilleur qualité mais cela sous-entend également plus de données a faire transiter sur le réseau ou encore un temps de vectorisation plus élevé. Un exemple de ce que donnerait le code barre en version « HD » :

Dans le cadre d’une analyse spectrale pour détecteur le moirée du a la fréquence de l’écran sur lequel on prend la photo, il est claire que la version HD est beaucoup plus intéressante.
Pour rappel : le moiré c’est ça

Arrive maintenant l’étape la moins marrante, construire et annoter la collection de données qui va servir a entrainer la machine a reconnaitre les images illégitimes. C’est une étape longue et couteuse a laquelle on échappe rarement dans ce genre de projet.
Le cout de l’opération est une raison de plus de s’intéresser a l’impact de quantité de données disponibles a l’entrainement d’un modèle sur les performances prédictives de ce même modèle.
Une fois que l’on a une quantité suffisante de données on va pouvoir enfin s’amuser un peu. Ont ainsi été recueillis 1250 photos de produits (code barre et produit) dont environ 1/3 sont des photos d’écrans illégitimes qu’il faut détecter. Selon le type de modèle que l’on souhaite utiliser, il peut être intéressant d’effectuer une analyse en composantes principales. Le principe de cette analyse réside dans la transformation des variables (nos dimensions) corrélées en nouvelles variables décorrélées les unes des autres les « composantes principales ». Lorsque l’on projette ses composantes, elles deviennent des axes, la projection si elle permet de distinguer les observations permet de réduire le nombre de variables et ainsi de rendre l’information moins redondante (on a également moins d’information a traiter). En appliquant une couleur différente a chaque image selon qu’elle soit légitime ou non voici une projection :
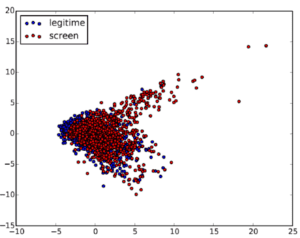
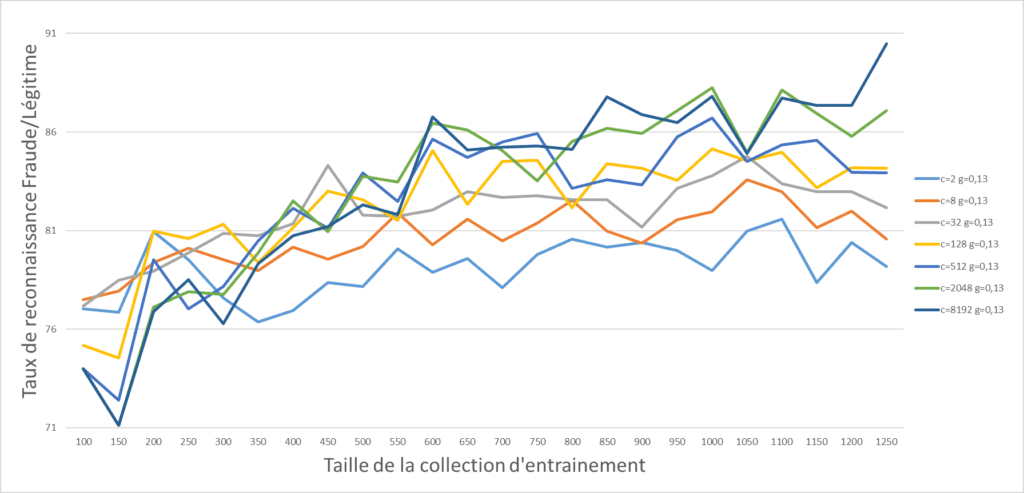
Comme on peut le voir la distinction, n’est pas évidente. Sans plus de précisions sur l’algorithme choisi passons a la partie entrainement. Les scores en ordonnées des graphes ci-dessous correspondent à un F1 Score classique moyennant précision et rappel. Étudions d’abord combien d’images de « HD » seraient nécessaire pour que la machine commence a donner un résultat acceptable.
Pour limiter les biais dans le protocole expérimental, parmi les 1250 images disponibles pour l’entrainement, on effectue a chaque pallier 100 tirages aléatoires et 100 entrainements (je suis sur que l’on peut faire mieux a ce niveau la), les résultats présentés sont ainsi moyennés. Les différentes courbes représentent un paramètre de tuning de l’algorithme.
Comme on peut le constater, les résultats sont loin d’être exceptionnel vu la répartition de la collection de données, dire que toutes les images sont acceptées aurait le même effet. Et qui plus est on arrive rapidement a un niveau de performance optimal. Et si on s’amuse maintenant a compresser les images a une taille de 120×120 pixels … puis on refait une vectorisation avant de recommencer l’entrainement du même algorithme.
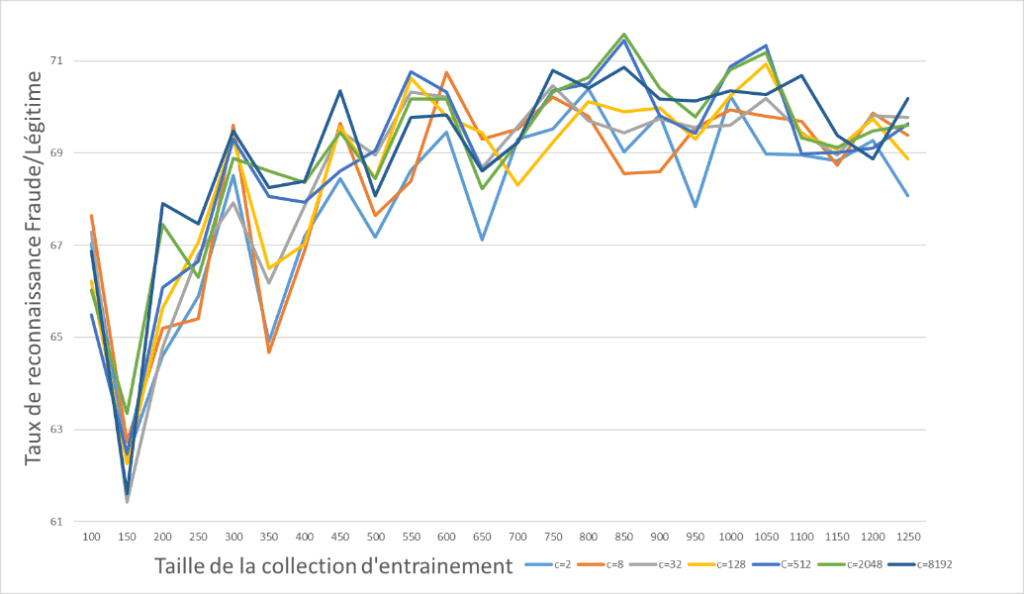
Le résultat est intéressant, avec moins d’images en entrainement, en utilisant moins de ressources (vu qu’il y a moins de données a utiliser), on arrive a résultat largement plus satisfaisant (+20% qui s’en plaindrait, maintenant on part de tellement loin que…). Toutefois, ce n’est pas très satisfaisant, on atteint rapidement un plateau de performances et plus de données ne permet pas d’obtenir de meilleurs résultats, il est peut-être temps de changer de famille d’algorithme.
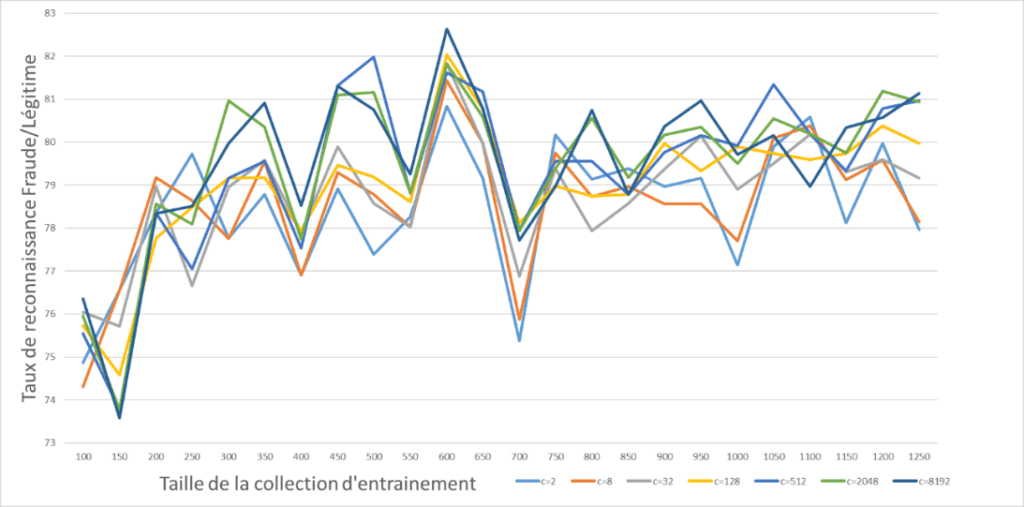
Repartons sur un nouvel algorithme avec des photos « HD » , le 1er point intéressant est que l’on arrive a dépasser le bon résultat obtenu précédemment avec des images compressés. Le 2ème point est que continuer d’ajouter des données améliore les performances et enfin, la variable de tuning a un impact important sur les performances avec un écart de plus de 30% entre un bon et mauvais choix de paramètre.
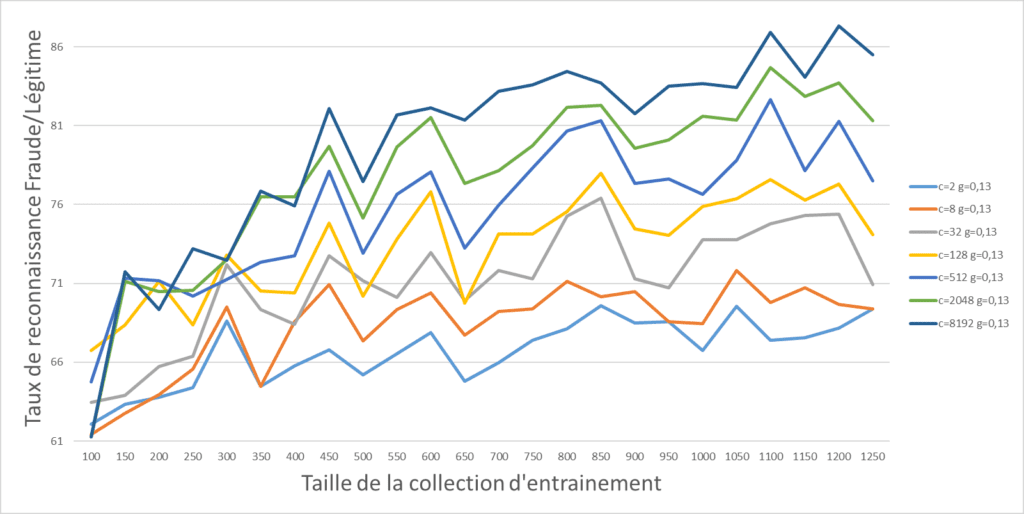
Par curiosité, la même expérience avec les images compressées permet d’atteindre un nouveau pallier de performances. On remarque encore un écart de 20% entre le meilleur et le « moins bon » choix de paramètre. Le niveau atteint ayant jugé satisfaisant et la campagne de création de la collection de données commençant à devenir vraiment onéreuse, il a été décidé de s’arrêter la. Puis de convenir d’une mise en production de l’algorithme en utilisant l’intégralité des données disponibles et en forçant la compression pour toutes les images qui seraient soumises au système.